Data-starved inference for high-dimensional point processes
Cutting-edge and critical applications in biology, network traffic analysis, astrophysics, and spectroscopy all rely upon our ability to perform fast and accurate inference on high-dimensional point processes using a meager supply of event-based data. In general, point processes arise when indirect observations of a physical phenomenon are collected by counting discrete events (such as photons hitting a detector, cars passing a highway sensor, packets traveling through an Internet router, or people interacting in a social network).
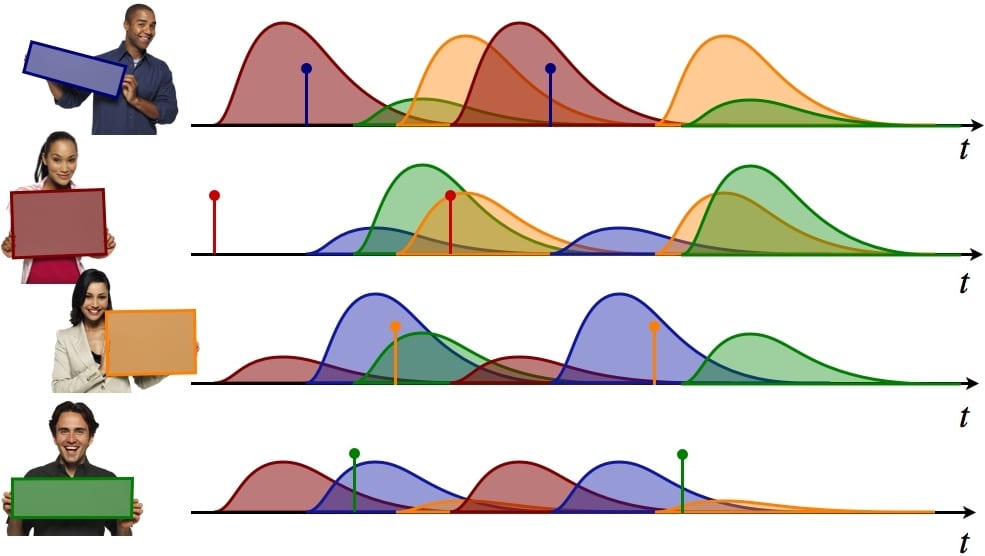
Illustration of Hawkes process
The challenge here is to use extremely small numbers of random events to perform inference on the underlying very high-dimensional and intrinsically complex phenomenon (e.g., distribution of tissue in the body, or distribution of traffic in a network). My work is focused on understanding and exploiting the complex interplay between low-dimensional or sparse models of signal structure and discrete event data generated by real-world systems.

Photon-limited image denoising. The multiscale method in (c) was representative of the state of the art in the early 2000s; since then, methods like BM3D [8], which exploit low-rank structure among the collection of all patches in an image, have emerged at the forefront of image denoising. Simply applying methods like BM3D (which were designed for Gaussian noise) directly to Poisson images yields poor results, as shown in (d). Applying the Anscombe transform to Poisson data generates approximately Gaussian data that can be processed using tools like BM3D, as demonstrated in (e). Methods designed explicitly for Poisson data can reveal additional structure, as shown in (f).
- J. Salmon, Z. Harmany, C. Deledalle, and R. Willett, “Poisson noise reduction with non-local PCA,” Journal of Mathematical Imaging and Vision, vol. 48, no. 2, pp. 279–294, arXiv:1206:0338, 2014.
- A. Oh, Z. Harmany, and R. Willett, “To e or not to e in Poisson image reconstruction,” ICIP 2014. “Top 10% Paper”.
- E. Hall, G. Raskutti, and R. Willett, ”Inference of High-dimensional Autoregressive Generalized Linear Models.” arXiv:1605.02693, 2016.
- A. Yankovich, C. Zhang, A. Oh, T. Slater, F. Azough, R. Freer, S. Haigh, R. Willett, P. Voyles, “Non-rigid registration and non-local principle component analysis to improve electron microscopy spectrum images,” Nanotechnology, vol. 27, no. 36, 2016.
Poisson compressed sensing
The goal of compressive sampling or compressed sensing (CS) is to replace conventional sampling by a more efficient data acquisition framework, which generally requires fewer sensing resources and exploits sparsity and structure in the underlying signal. This paradigm is particularly enticing whenever the measurement process is costly or constrained in some sense. For example, in the context of photon-limited applications (such as low-light imaging), the photomultiplier tubes used within sensor arrays are physically large and expensive. However, photon-limited measurements are commonly modeled with a Poisson probability distribution, posing significant theoretical and practical challenges in the context of CS. My lab has addressed some of the major theoretical challenges associated with the application of compressed sensing to practical hardware systems and developed performance bounds for compressed sensing in the presence of Poisson noise. We considered two novel sensing paradigms, based on either pseudo- random dense sensing matrices or expander graphs, which satisfy physical feasibility constraints. In these settings, as the overall intensity of the underlying signal increases, an upper bound on the reconstruction error decays at an appropriate rate (depending on the compressibility of the signal), but for a fixed signal intensity, the error bound actually grows with the number of measurements or sensors. In other words, my lab found that incorporating real-world constraints into our measurement model has a significant and adverse impact on the expected performance of a Poisson CS system, suggesting that compressed sensing may be fundamentally difficult for certain optical systems and networks.
- X. Jiang, G. Raskutti, and R. Willett, “Minimax Optimal Rates for Poisson Inverse Problems with Physical Constraints,” IEEE Transactions on Information Theory, arXiv:1403.6532, 2014.
- M. Raginsky, S. Jafarpour, Z. Harmany, R. Marcia, R. Willett, and R. Calderbank. “Performance bounds for expander-based compressed sensing in Poisson noise.” IEEE Transactions on Signal Processing, vol. 59, no. 9, 2011.
- M. Raginsky, R. Willett, Z. Harmany, and R. Marcia. “Compressed sensing performance bounds under Poisson noise,” IEEE Transactions on Signal Processing Volume 58, Issue 8, pp 3990-4002, 2010.
Computational imaging and spectroscopy
Traditionally, optical sensors have been designed to collect the most directly interpretable and intuitive measurements possible. For example, a standard digital camera directly measures the brightness of a scene at different spatial locations. The problem is that the combination of direct measurement systems with large or expensive (e.g., infrared) sensors typically translates into low system resolution. Recent advances in the fields of image reconstruction, inverse problems, and compressed sensing indicate, however, that substantial performance gains may be possible in some contexts via computational methods. In particular, by designing optical sensors to collect carefully chosen measurements of a scene, we can use sophisticated computational methods to infer more information about critical structure and content. As described above, photon limitations have a significant impact on the performance of computational imagers, so we face complex tradeoffs among photon efficiency (i.e., how much of the available light in harnessed), measurement diversity, and resolution. My lab has helped develop novel new computational optical systems for spectroscopy and spectral imaging that address these challenges. Our approach yields up to an 84% reduction in error from conventional approaches.
- Scott McCain, Rebecca Willett, and David Brady. “Multi-excitation Raman spectroscopy technique for fluorescence rejection“, Optics Express, vol 16, no. 15, pp 10975-10991.
- Ashwin Wagadarikar, Renu John, Rebecca Willett, and David Brady, “Single disperser design for coded aperture snapshot spectral imaging,” Applied Optics, vol. 47, no. 10, pp. B44-B51, 2008.
- Michael Gehm, Renu John, David Brady, Rebecca Willett, and Timothy Schultz. ”Single-shot compressive spectral imaging with a dual-disperser architecture,” Optics Express, Vol. 15, No. 21, pp. 14013-14027, 2007.
- Z. Harmany, R. Marcia, and R. Willett. “Spatio-temporal Compressed Sensing with Coded Apertures and Keyed Exposures.” arXiv:1111.7247, 2011.
Machine learning for large-scale data streams
High-velocity streams of high-dimensional data pose significant “big data” analysis challenges across a range of applications and settings. Modern sensors are collecting very high-dimensional data at unprecedented rates, often from platforms with limited processing power. These large datasets allow scientists and analysts to consider richer physical models with larger numbers of variables, and thereby have the potential to provide new insights into the underlying complex phenomena. While recent advances in online learning have led to novel and rapidly converging algorithms, these methods are unable to adapt to nonstationary environments arising in real-world problems. My lab has developed methods for processing such data “on the fly”. One contribution is a dynamic mirror descent framework which yields low theoretical regret bounds via accurate, adaptive, and computationally efficient algorithms which are applicable to broad classes of problems. The methods are capable of learning and adapting to an underlying and possibly time-varying dynamical model. Empirical results in the context of dynamic texture analysis, solar flare detection, sequential compressed sensing of a dynamic scene, traffic surveillance, tracking self-exciting point processes and network behavior in the Enron email corpus support the core theoretical findings. More recent work proposes a method of online data thinning, in which large-scale streaming datasets are winnowed to preserve unique, anomalous, or salient elements for timely expert analysis. At the heart of this approach is an online anomaly detection method based on dynamic, low-rank Gaussian mixture models. The low-rank modeling mitigates the curse of dimensionality associated with anomaly detection for high-dimensional data, and recent advances in subspace clustering and subspace tracking allow the proposed method to adapt to dynamic environments.
- X. Jiang and R. Willett, “Online Data Thinning via Multi-Subspace Tracking.” arXiv:1609.03544, 2016. Code.
- E. Hall and R. Willett, “Online convex optimization in dynamic environments,” IEEE Journal of Selected Topics in Signal Processing – Signal Processing for Big Data, vol. 9, no. 4, arXiv:1307:5944, 2015. code
Nonlinear models in machine learning
Most modern methods in sparse and low-rank representations of data in machine learning are inherently linear: features combine linearly to predict outcomes, or high-dimensional observations lie along a subspace or hyperplane. However, this linear assumption is overly restrictive in many practical problems. My lab is developing novel methods for nonlinear matrix completion – i.e., for estimating missing elements of high-dimensional data without the linear constraint. We are considering both single index models (which assume an unknown nonlinear corruption of the data must be inferred to accurately estimate missing data) and union of subspace models (which assume data lie along one among several candidate subspaces or hyperplanes).
- D. Pimentel-Alarcon, L. Balzano, R. Marcia, R. Nowak, and R. Willett, “Group-sparse subspace clustering with missing data.” IEEE Statistical Signal Processing Workshop, 2016.
- R. Ganti, L. Balzano, and R. Willett, “Matrix Completion Under Monotonic Single Index Models,” in Proc. Neural Information Processing Systems, 2015.